На вебинаре «Аналитика и искусственный интеллект на производстве: как повысить эффективность и сократить потери с помощью данных», организованном ГК «КорусКонсалтинг», эксперт рассказала о преимуществах использования инструментов ИИ, алгоритмах работы с данными и одном из вариантов обучения сотрудников.
 Особенности производства в России спикер, руководитель группы Data Science Екатерина Торсукова охарактеризовала так: «Если нет необходимости что-либо менять, не меняйте ничего». На развитие производства влияют ряд внешних факторов, таких как стабильный спрос на продукцию, наличие ресурсов и слабые экологические ограничения, что не стимулирует решать задачи по оптимизации (как правило, их откладывают «на потом»).
Особенности производства в России спикер, руководитель группы Data Science Екатерина Торсукова охарактеризовала так: «Если нет необходимости что-либо менять, не меняйте ничего». На развитие производства влияют ряд внешних факторов, таких как стабильный спрос на продукцию, наличие ресурсов и слабые экологические ограничения, что не стимулирует решать задачи по оптимизации (как правило, их откладывают «на потом»).
Среди внутренних факторов спикер выделила старые производственные системы, подчиненные плановой экономике, контроль входной и выпускаемой продукции.
По-прежнему дают о себе знать наследственный принцип формирования кадрового состава («о цифровизации и не слышали»), сопротивление изменениям и слабое влияние технологий на производственные процессы. Особенно актуальны данные факторы для градообразующих предприятий.
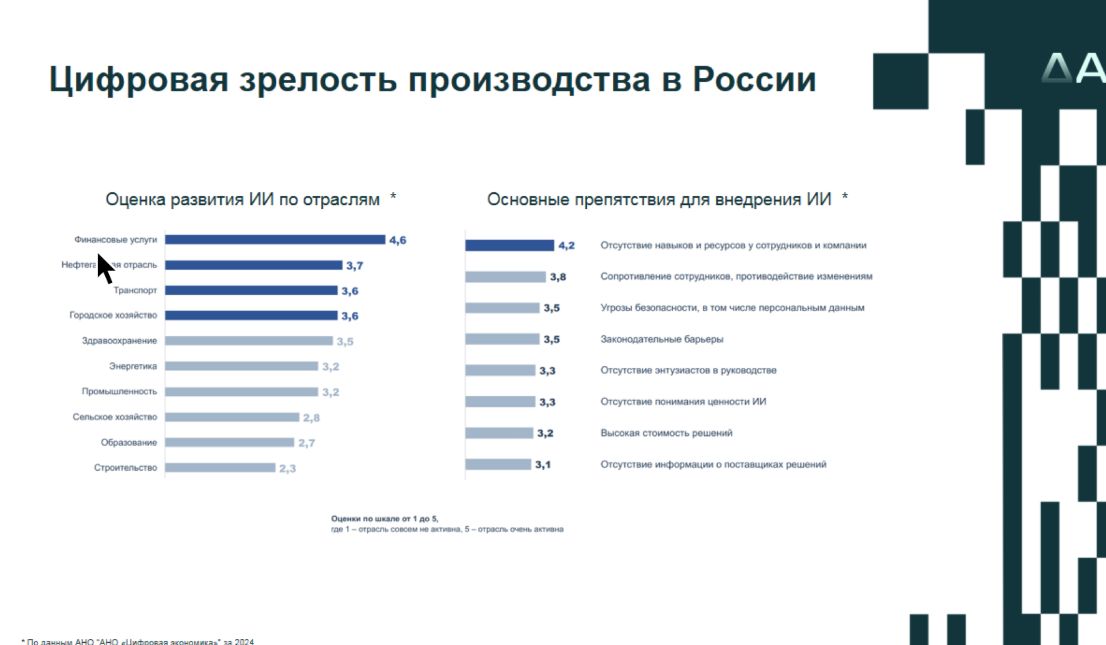 Согласно данным агентства «Цифровая экономика», которое исследовало вопрос цифровой зрелости производства в России, промышленность по уровню внедрения инструментов искусственного интеллекта, находится во второй половине перечня. В числе основных проблем на пути продвижения технологии эксперты называют человеческий фактор, законодательные и бюрократические барьеры. «Поскольку производство – это система повышенной опасности, существует много регламентов. И для внедрения новых систем надо перерабатывать старые регламенты», – пояснила Екатерина Торсукова. В этом же ряду препятствий – отсутствие понимания как внедрять ИИ, высокая стоимость решений, предлагаемых на рынке.
Согласно данным агентства «Цифровая экономика», которое исследовало вопрос цифровой зрелости производства в России, промышленность по уровню внедрения инструментов искусственного интеллекта, находится во второй половине перечня. В числе основных проблем на пути продвижения технологии эксперты называют человеческий фактор, законодательные и бюрократические барьеры. «Поскольку производство – это система повышенной опасности, существует много регламентов. И для внедрения новых систем надо перерабатывать старые регламенты», – пояснила Екатерина Торсукова. В этом же ряду препятствий – отсутствие понимания как внедрять ИИ, высокая стоимость решений, предлагаемых на рынке.
Алгоритм работы с данными
Работа с данными – один из аспектов, который следует учитывать при внедрении ИИ. Далеко не на каждом предприятии специалисты используют потоковые данные (с датчиков оборудования, данные результатов мониторинга видеопотока), которые стоит анализировать. Большое количество информации можно получать на основе производственных и операционных данных.
 Алгоритм работы с данными эксперт представила на примере системы принятия решений на металлургическом предприятии (до внедрения систем продвинутой аналитики и после). Процесс легирования стали, добавления в ее состав примесей для улучшения свойств материала требует значительных энергетических ресурсов. Данные о первоначальном составе стали и добавок, времени их внесения фиксируются оператором вручную в производственном журнале (табличном файле). Данные о температуре нагрева собираются с датчиков производственного оборудования, сбор не автоматизирован. Легирующие элементы добавляются исходя из опыта сотрудников производства. Контролируется только качество готовой продукции, контроль за оптимизацией расхода ресурсов и материалов отсутствует.
Алгоритм работы с данными эксперт представила на примере системы принятия решений на металлургическом предприятии (до внедрения систем продвинутой аналитики и после). Процесс легирования стали, добавления в ее состав примесей для улучшения свойств материала требует значительных энергетических ресурсов. Данные о первоначальном составе стали и добавок, времени их внесения фиксируются оператором вручную в производственном журнале (табличном файле). Данные о температуре нагрева собираются с датчиков производственного оборудования, сбор не автоматизирован. Легирующие элементы добавляются исходя из опыта сотрудников производства. Контролируется только качество готовой продукции, контроль за оптимизацией расхода ресурсов и материалов отсутствует.
Таким образом, до внедрения системы продвинутой аналитики на производстве существовала, по словам спикера, система «файликов и журналов», в которые вручную заносились результаты лабораторных исследований.
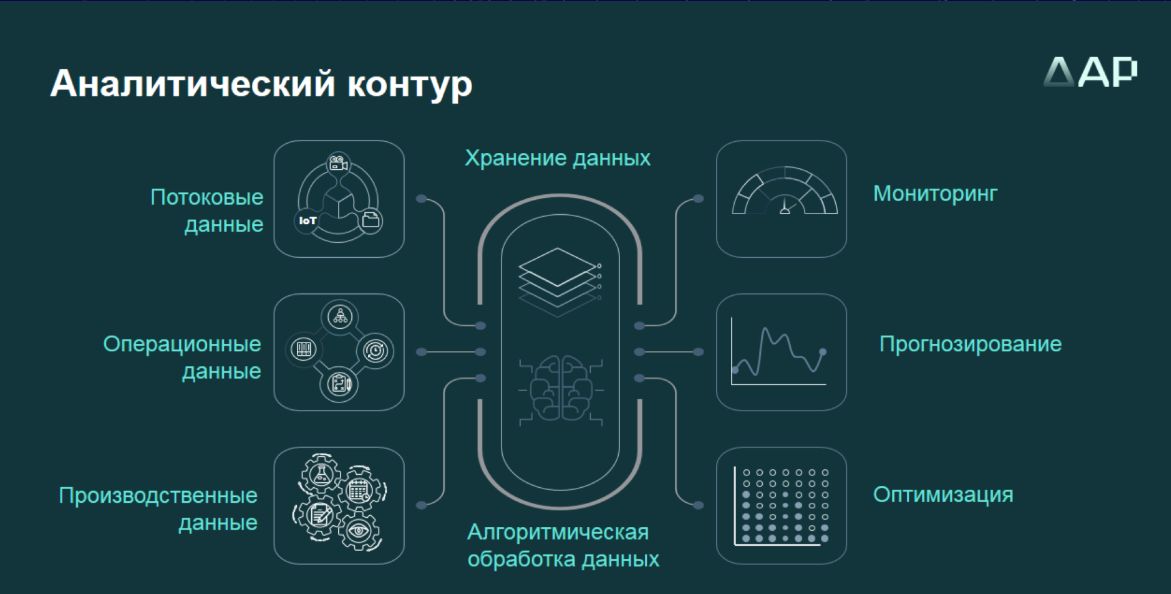 На первом этапе проекта внедрения была обеспечена автоматизация ввода лабораторных данных, данных итераций производственного процесса, налажен быстрый обмен данными между производством и лабораторией. Затем был автоматизирован сбор данных и организовано их хранение. Для этого внедрили систему мониторинга производства на базе IoT-инструментов, обеспечили интеграцию системы ввода данных и IoT-системы. На следующем этапе был сформирован аналитический контур: созданы аналитические системы мониторинга технологического процесса на базе продвинутой аналитики, а также модель, рассчитывающая оптимальное значение легирующих добавок и мощности для достижения температурного режима исходя из параметров исходного сырья.
На первом этапе проекта внедрения была обеспечена автоматизация ввода лабораторных данных, данных итераций производственного процесса, налажен быстрый обмен данными между производством и лабораторией. Затем был автоматизирован сбор данных и организовано их хранение. Для этого внедрили систему мониторинга производства на базе IoT-инструментов, обеспечили интеграцию системы ввода данных и IoT-системы. На следующем этапе был сформирован аналитический контур: созданы аналитические системы мониторинга технологического процесса на базе продвинутой аналитики, а также модель, рассчитывающая оптимальное значение легирующих добавок и мощности для достижения температурного режима исходя из параметров исходного сырья.
 Как показывает практика, эффект от внедрения подобных систем заключается в следующем: снижение времени принятия решений и объема ручного труда, сведение к минимуму ошибок в расчетах, сокращение объема брака, операционных расходов и увеличение выручки, а также более предсказуемый производственный процесс.
Как показывает практика, эффект от внедрения подобных систем заключается в следующем: снижение времени принятия решений и объема ручного труда, сведение к минимуму ошибок в расчетах, сокращение объема брака, операционных расходов и увеличение выручки, а также более предсказуемый производственный процесс.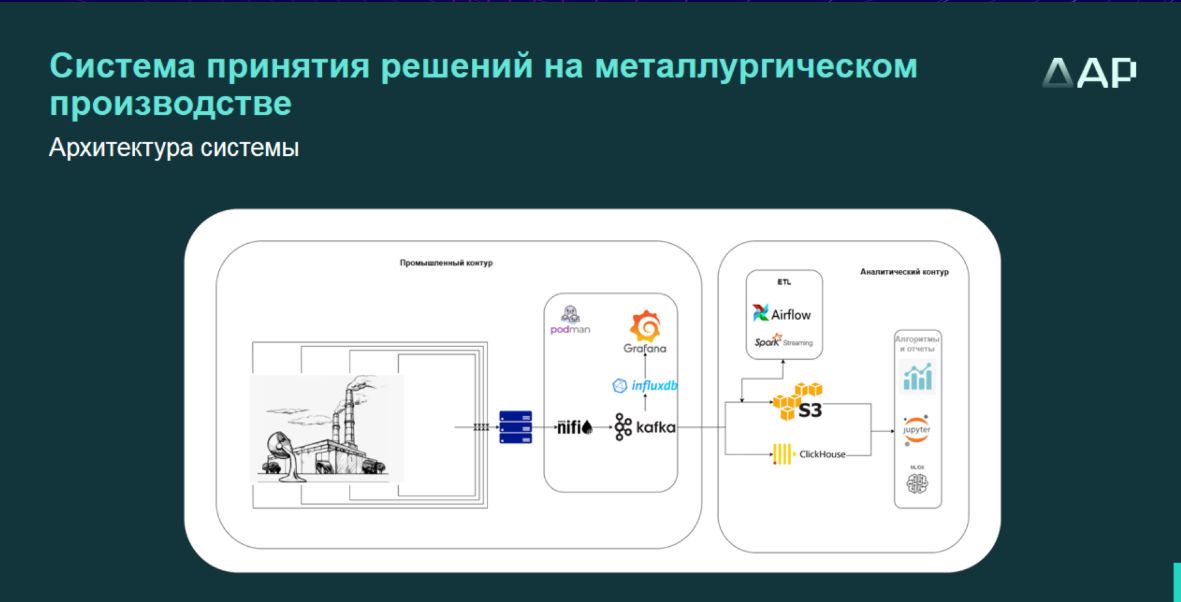
Пошаговая трансформация
Для наведения порядка в хранении и использовании данных не обойтись без трансформации. Приступать к ней эксперт рекомендует с анализа и аудита имеющихся систем. Затем на очереди разработка новых и доработка текущих решений, интеграция корпоративных систем, консолидация данных в едином хранилище.
Следующие шаги – разработка и утверждение методологий расчета показателей и регламентов работы с ними, выстраивание бизнес-процессов сбора данных, разработка моделей расчета целевых показателей и их автоматизация. Еще один шаг – построение в BI витрин данных.
Особое внимание эксперт уделила механизму построения аналитического контура, наличие которого позволяет мониторить, прогнозировать и оптимизировать. Мониторинг и прогнозирование связаны с историческими данными.
В состав инфраструктуры для аналитики входят источники данных, механизмы и инструменты интеграции данных, базы и витрины данных, аналитическое хранилище данных (с инструментами low-code), инструменты визуализации и отчетности. Архитектура системы принятия решений на упомянутом металлургическом производстве включает в себя два контура – производственный и аналитический. Правильно организованный процесс хранения данных имеет большое значение для использования инструментов ИИ, поскольку с помощью методов искусственного интеллекта анализируются исторические данные («если не хранить историю, обучаться будет не на чем»).
Сценарии и задачи
Эксперт рассказала о передовых сценариях использования данных, на основе которых можно решать задачи прогнозирования и оптимизации бизнес-показателей, логистических процессов, кластеризации и классификации, осуществлять мониторинг безопасности и процессов, развивать базу знаний (в частности, создавать единый портал для поиска в базе знаний с помощью чат-бота, генерировать техническую документацию по шаблонам и т. д.).
 Один из сценарных кейсов предусматривал создание системы детектирования аварийных ситуаций на трубопроводе. При этом предстояло выбрать, что использовать: ML-модель или цифровой двойник. Различие между ними в том, что в первом случае модель строится только исходя из внешнего поведения, работа исключительно с входными и выходными данными. При выборе цифрового двойника используется математическое моделирование, большой вес имеют внутренние процессы и проработка взаимосвязей.
Один из сценарных кейсов предусматривал создание системы детектирования аварийных ситуаций на трубопроводе. При этом предстояло выбрать, что использовать: ML-модель или цифровой двойник. Различие между ними в том, что в первом случае модель строится только исходя из внешнего поведения, работа исключительно с входными и выходными данными. При выборе цифрового двойника используется математическое моделирование, большой вес имеют внутренние процессы и проработка взаимосвязей.
 Использованию ИИ-технологий на конкретных промышленных предприятиях не способствует дефицит сотрудников, отвечающих за работу с данными. На вебинаре эксперт представила методологию Citizen Data Science, направленную на расширение возможностей сотрудников, которые не являются специалистами по обработке данных. Суть подхода, набирающего популярность, в том, что заинтересованным технологам (как вариант, аналитикам, операторам) обеспечивается доступ к инструментам самообслуживания (low-code), позволяющим им самостоятельно загружать, обрабатывать и анализировать данные. Сотруднику, который сосредоточен на решении конкретных бизнес-проблем с помощью данных, компания обеспечивает обучение и поддержку. Анализ данных проводится поэтапно с постоянным уточнением задач, интерпретацией результатов.
Использованию ИИ-технологий на конкретных промышленных предприятиях не способствует дефицит сотрудников, отвечающих за работу с данными. На вебинаре эксперт представила методологию Citizen Data Science, направленную на расширение возможностей сотрудников, которые не являются специалистами по обработке данных. Суть подхода, набирающего популярность, в том, что заинтересованным технологам (как вариант, аналитикам, операторам) обеспечивается доступ к инструментам самообслуживания (low-code), позволяющим им самостоятельно загружать, обрабатывать и анализировать данные. Сотруднику, который сосредоточен на решении конкретных бизнес-проблем с помощью данных, компания обеспечивает обучение и поддержку. Анализ данных проводится поэтапно с постоянным уточнением задач, интерпретацией результатов.
 Преимущество подхода – в повышении вовлеченности сотрудников, которые лучше понимают данные. Однако методология не лишена и минусов: потенциал для ошибок, допускаемых непрофильными специалистами, ограничения в объемах обработанных данных, в сложных алгоритмах (использовать можно только базовую функциональность инструментов), необходимость поддержки.
Преимущество подхода – в повышении вовлеченности сотрудников, которые лучше понимают данные. Однако методология не лишена и минусов: потенциал для ошибок, допускаемых непрофильными специалистами, ограничения в объемах обработанных данных, в сложных алгоритмах (использовать можно только базовую функциональность инструментов), необходимость поддержки.



