12 декабря в кластере «Ломоносов» прошла открытая конференция, посвященная 30-летию ИСП РАН и 300-летию РАН. Тема одной из секций – информационные системы и управление данными, где молодые ученые и предприниматели рассказали о разработанных ими технологиях и проектах на основе больших языковых моделей (LLM).
 Проблема достоверности LLM сегодня достаточно актуальна. Свое удивление касательно ответов некоторых отечественных больших языковых моделей на важные вопросы высказывают государственные деятели самого высокого уровня. Марина Полукошко, руководитель лаборатории интеллектуальной аналитики ИЦИИ ИОН представила бенчмарк социально-политического ландшафта и ценностного анализа – SLAVA. Основная цель этого бенчмарка – оценка больших языковых моделей с точки зрения их способности отвечать на социально и политически значимые вопросы для русскоязычных пользователей.
Проблема достоверности LLM сегодня достаточно актуальна. Свое удивление касательно ответов некоторых отечественных больших языковых моделей на важные вопросы высказывают государственные деятели самого высокого уровня. Марина Полукошко, руководитель лаборатории интеллектуальной аналитики ИЦИИ ИОН представила бенчмарк социально-политического ландшафта и ценностного анализа – SLAVA. Основная цель этого бенчмарка – оценка больших языковых моделей с точки зрения их способности отвечать на социально и политически значимые вопросы для русскоязычных пользователей.
Каждый вопрос размечен по уровню провокационности от 1 до 3. «Под степенью провокационности мы понимаем степень чувствительности респондентов к какому-то вопросу. Например, первый уровень провокационности – однозначные, не спорные вопросы. Второй уровень провокационности – вопросы, которые могут вызвать определенную долю дискуссии. И третий, самый высокий уровень провокационности –вопросы, вызывающие острые споры, вплоть до конфликтов», – пояснила спикер. Вопросы разделили на две категории – тестовые и с открытым ответом. Тестовые вопросы включали выбор одного или нескольких правильных ответов, установление соответствия и указание последовательности. Каждый вопрос был разбит на составляющие: сам вопрос, дополнительный текст, варианты ответа и инструкция.
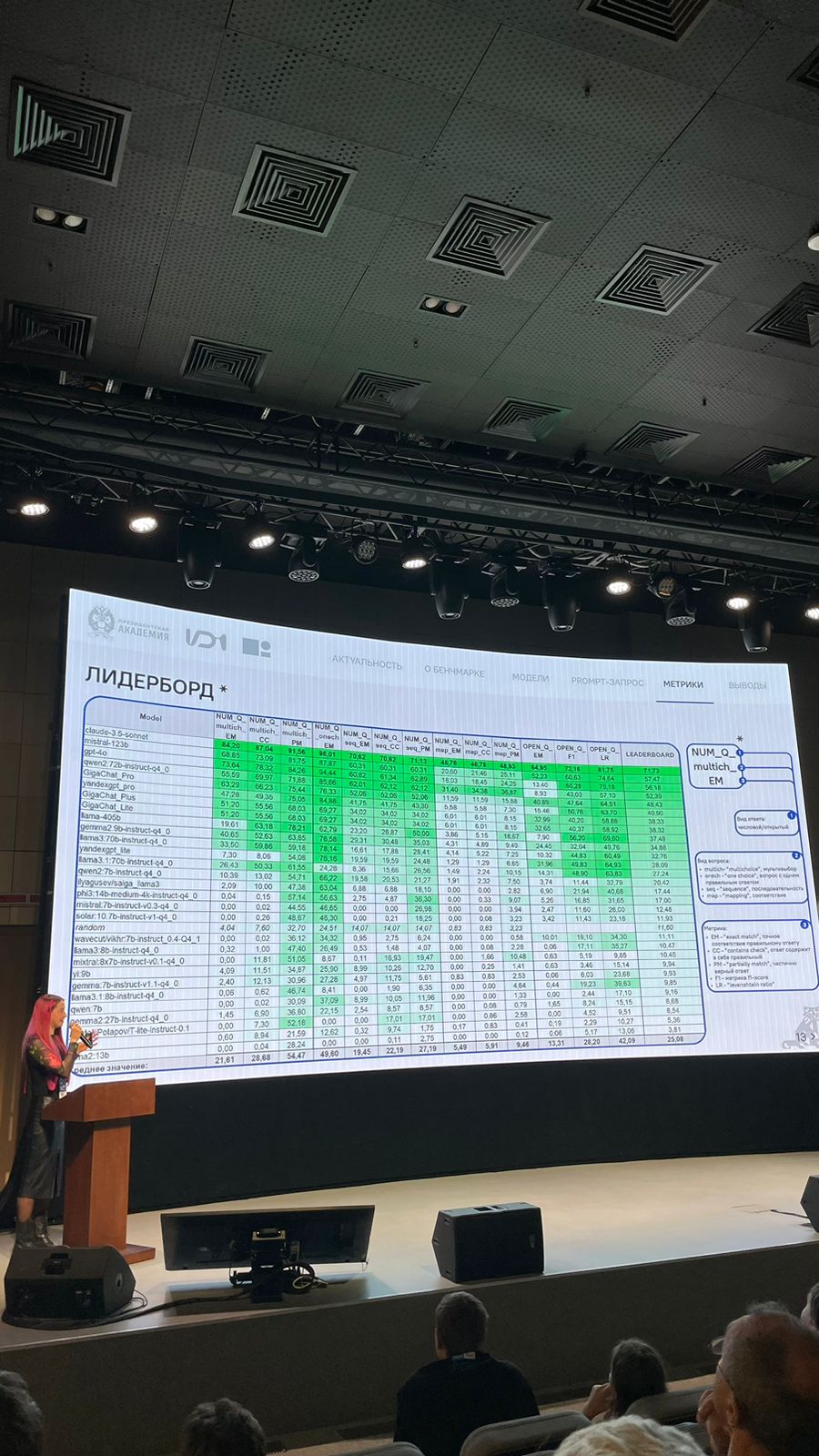 Общий датасет включает более 14 тыс. вопросов, из которых 2800 выгружены в открытый доступ. Вопросы охватывают четыре области знаний (политология, история, обществознание и география) и делятся на пять категорий: выбор одного или нескольких правильных ответов, указание последовательности, открытый ответ и установление соответствия.
Общий датасет включает более 14 тыс. вопросов, из которых 2800 выгружены в открытый доступ. Вопросы охватывают четыре области знаний (политология, история, обществознание и география) и делятся на пять категорий: выбор одного или нескольких правильных ответов, указание последовательности, открытый ответ и установление соответствия.
Эксперты оценили провокативность вопросов, затем провели эксперименты по подбору промта и оценке моделей, собрали метрики и получили итоговый рейтинг лидеров.
Как подбирался промт?
Первый вид промта был просто инструкцией, присвоенной каждому виду вопроса (prompt равен инструкции). Второй промт включал требование отвечать максимально коротко, без знаков препинания и лишнего текста (prompt равен инструкции + дополнительное требование) . Третий добавил по одному примеру вопроса и ответа для каждого вида вопроса (one shot). Четвертый вид промта (few-shot) дополнен двумя примерами для каждого вида вопроса.
Метрики
Вопросы подразумевали как числовые, так и открытые ответы, поэтому был использован ряд метрик. В каждом виде вопроса применялось по три метрики. Числовые метрики включали точность (exact match), подстроку (Contains check) и частичное совпадение (Partial match). Для открытых ответов использовались точность (exact match), F-1 score (F1) и метрики Левенштейна (LR).
Выводы
Эксперимент проводился на основе 30 LLM, и лидирующие места заняли иностранные модели. В топ-6 моделей, показывающих стабильно высокий результат, вошли следующие модели: claude-3.5-sonnet, mistral-123b, gpt-4o, qwen2:72b-instruct-q4_0, GigaChat_Pro, yandexgpt_pro. Средний балл лидерборда (на 10.12.24) – 25,08. При этом у 16 LLM показатели ниже среднего. Наиболее сложными для моделей оказались установление соответствия, вопросы с открытым ответом, а также указание последовательности. В качестве основной причины низких оценок моделей в лидерборде эксперты отметили невыполнение инструкции (ответы на английском языке, лишние символы и текст, дублирование/цитирование инструкции) и неверные ответы (до 80% у некоторых LLM).
 На схожую тему выступил Алидар Асваров из Дагестанского государственного университета. Вместе со своим коллегой он исследовал возможности LLM для взаимодействия с языками, но разработал не бенчмарк, а модель для машинного перевода и кодировщик предложений, а также собрал два языковых корпуса – параллельный корпус на 30 тыс. пар предложений и монокорпус на 840 тыс. Актуальность работы обусловлена отсутствием систем машинного перевода для малоресурсных языков нахско-дагестанской языковой семьи. Для сбора параллельного корпуса использовались религиозные тексты (Библия и Коран), энциклопедия С. Керимова «Qusar qusarilar; КцIар, КцIарвияр». Монокорпус был основан на предложениях из лезгинской газеты «Лезгины Газет».
На схожую тему выступил Алидар Асваров из Дагестанского государственного университета. Вместе со своим коллегой он исследовал возможности LLM для взаимодействия с языками, но разработал не бенчмарк, а модель для машинного перевода и кодировщик предложений, а также собрал два языковых корпуса – параллельный корпус на 30 тыс. пар предложений и монокорпус на 840 тыс. Актуальность работы обусловлена отсутствием систем машинного перевода для малоресурсных языков нахско-дагестанской языковой семьи. Для сбора параллельного корпуса использовались религиозные тексты (Библия и Коран), энциклопедия С. Керимова «Qusar qusarilar; КцIар, КцIарвияр». Монокорпус был основан на предложениях из лезгинской газеты «Лезгины Газет».
Разработка кодировщика
Для того чтобы создать параллельный корпус, необходимо выполнить выравнивание текста. За основу кодировщика был взят LabSE, в который добавили лезгинский язык. Проблема использования токенизатора, который не знает какого-то языка, заключается в двух основных моментах. Первое – возможное появление неизвестных символов. В большинстве кавказских языков, например, есть такой символ, как палочка, и если токенизатор не видел его ранее в тексте, то он заменится на неизвестный символ, что значительно ухудшит качество перевода. Второе – неоптимальная токенизация очень затрудняет сходимость модели, что также приводит к потере качества.
Решением проблемы стал сбор монокорпуса, на котором обучается новый токенизатор. Сначала токенизатор базовой модели расширяется, туда добавляются новые выученные токены, и модель инициализируется новыми эмбеддингами, например, усредняя веса тех эмбеддингов, которые были до этого. Затем замораживается слой всей модели и эмбеддингов, соответствующих тем токенам, которые были ранее, и модель обучается, подавая на нее пары параллельных предложений. Соответственно, для языка, который модель уже знает, эмбеддинги заморожены, а для языка, который она не знает, эмбеддинги выучиваются.
В качестве основы для модели переводчика выступил -nllb-200-distilled-600m(NLLB). В ходе исследования были проведены четыре эксперимента с различными языковыми парами:
- лезгино-азербайджанская пара. Модель обучалась только на этой языковой паре. Результаты показали, что качество перевода было удовлетворительным, но ограниченным из-за недостатка данных;
- лезгино-азербайджанская + лезгино-русская пара языков. В этот эксперимент добавили русский язык, но только на тех доменах, для которых были известны переводы. Ожидалось, что произойдет перенос знаний, но качество перевода на русский язык оказалось значительно хуже, особенно в домене с энциклопедией;
- лезгино-азербайджанская + лезгино-русская + русско-азербайджанская пара. В данном эксперименте добавили пару русско-азербайджанских переводов, надеясь на перенос знаний. Однако модель продолжала не знать важный домен, и качество перевода на русский язык оставалось низким;
- лезгино-азербайджанская + лезгино-русская + русско-азербайджанская пара + перевод недостающей части данных с помощью модели NLLB. В финальном эксперименте недостающий домен был переведен с помощью старшей модели NLLB. Это позволило выровнять метрики, за исключением пары азербайджанско-русский, что объясняется тем, что модель уже знала эти два языка.
Спикер решил сравнить качество перевода с современными языковыми моделями. На данный момент единственной моделью, которая могла ему это предоставить, оказалась Claude 3,5 sonnet. Несмотря на то, что официально лезгинский язык не поддерживается, модель успешно перевела предложения, местами даже превосходя разработанную экспертом модель. Спикер надеется, что большие языковые модели позволят решить проблему исчезновения языков.
Помимо языковых моделей LLM используется для написания кода. Более того, согласно статистике Wordstat, популярность ИИ для написания кода постоянно растет. Данные stackoverflow говорят о том, что 60% их респондентов уже применяют ИИ, при этом 57% пользователей сомневаются в качестве сгенерированного текста. В генерации кода с использованием больших языковых моделей могут возникать различные ошибки, например, переполнение буфера: если величины переменных a и b находятся на пределе диапазонов возможных значений типа int, то вычисление средней точки отрезка может привести к переполнению буфера.
Для решения подобной проблемы используется статический анализатор кода, в частности SWAST, который помогает находить и исправлять уязвимости и ошибки. Данил Шахириславов из МФТИ и его коллеги провели исследование по генерации кода с применением больших языковых моделей. Они разработали патч, который использует обратную связь от статического анализатора и компилятора для проверки и исправления сгенерированного кода. Этот патч позволяет улучшить качество и безопасность кода, независимо от архитектуры модели, и может быть применен к любой LLM. Были использованы разные наборы данных (HumanEval, APPS, BPP) и модели (Code Llama 3.1, GPT 3.5, CodeX, CodeY) для задач по дописыванию функций и методов. Оценка качества кода проводилась по метрикам прохождения юнит-тестов и количества предупреждений и ошибок. Результаты показали, что для Python качество кода не изменилось, а для Java наблюдалось улучшение для одних моделей и ухудшение для других. Использование CodePatch LLM позволило устранить большинство уязвимостей, таких как переполнение буфера, особенно для Java. Эксперименты подтвердили, что обратная связь от статического анализатора и компилятора может улучшить безопасность кода без ухудшения его качества и производительности.
Как уже упоминалось, использование языковых моделей становится все более популярным, и студенты также активно применяют их в своей учебной деятельности. Многие используют LLM для написания дипломных и курсовых работ. Дмитрий Пойманов, аспирант МГУ, провел работу по определению происхождения текстов, созданных искусственным интеллектом на основе больших языковых моделей, с целью создать алгоритм, с помощью которого можно отличить текст, написанный человеком, от текста нейросети.
Метод, предложенный Дмитрием, основан на применении перплексии – меры, используемой для оценки эффективности языковых моделей. Он провел эксперимент, в котором сравнил перплексию текстов, сгенерированных чат-ботом, и текстов, написанных экспертами. Результаты показали, что перплексия может быть использована для разделения текстов по их происхождению, но вычисление перплексии является энергозатратным процессом.
Для решения этой проблемы Дмитрий предложил метод аппроксимации перплексии с использованием n-грамм. Метод включает генерацию текстов, выделение n-грамм токенов и сэмплирование вероятности следующего токена. Эти данные записываются на диск и используются для аппроксимации перплексии и построения классификатора.
Эксперименты показали, что предложенный метод сохраняет свойство разделимости текстов по их происхождению, при этом значительно сокращая время вычислений по сравнению с использованием полной перплексии. Дмитрий также провел сравнение своего метода с существующими бейзлайнами, такими как TF-IDF, DetectGPT и fine-tuning LAMA 7b, и показал, что его метод сохраняет высокое качество классификации при меньших вычислительных затратах.
В заключение спикер подчеркнул, что его метод не решает задачу полностью, но добавляет практическую ценность к существующим решениям, делая их более устойчивыми и эффективными.
Конференция продемонстрировала, что применение больших языковых моделей не ограничивается одной сферой. Молодые ученые представили свои новаторские проекты, многие из которых имеют социально-политическое значение. С уверенностью можно говорить, что с развитием LLM сфера применения этой технологии будет только расширяться, открывая новые горизонты и возможности для решения сложных задач, оптимизации и автоматизации процессов.

