
Hadoop евангелист, Teradata
Когда разговор заходит о больших данных, как правило, говорят о платформе Hadoop или элементах так называемой экосистемы Hadoop. Давайте разберемся, что представляет собой эта платформа сегодня. Историки развития технологии больших данных обычно рассказывают о том, как две научные публикации специалистов компании Google изменили мир обработки данных, однако без краткого экскурса в историю Hadoop трудно понять нынешнюю ситуацию.
Предыстория больших данных
Итак, все началось с публикаций двух специалистов Google, в которых описывались модель распределенной обработки данных, получившая название MapReduce, и распределенная файловая система Google File System. На их основе группа разработчиков-энтузиастов создала платформу Hadoop, на которую обратили внимание такие мэтры ИТ-индустрии, как Yahoo и Facebook, став ведущими разработчиками этого проекта.
Изначальную архитектуру можно представить в виде трех слоев.
Первый слой – хранения данных. Изначально под слоем хранения данных подразумевалась исключительно распределенная файловая система Hadoop Distributed File System (HDFS). Она характеризуется высокой степенью устойчивости к выходу из строя отдельных узлов. Однако со временем начали появляться альтернативные варианты, такие как использование нереляционных БД (в первую очередь, конечно же, HBase, которая быстро стала частью всех значимых дистрибутивов Hadoop).
Второй слой представляет собой фреймворк обработки данных MapReduce (MR), реализующий одноименную модель группировки информации. Он разделяет процесс обработки данных на два этапа: Map – генерация на основе входящих данных пар типа ключ –значение и Reduce – группировка по ключу значений из пар первого этапа, ставших продуктом первого этапа. Благодаря такому подходу достигается высокая степень «локальности данных», т. е. информация обрабатывается преимущественно на тех узлах системы, на которых она хранится, что позволяет минимизировать сетевое взаимодействие между элементами системы.
Можно сказать, что два первых слоя вместе и представляют собой то, что изначально понималось под словом Hadoop. Однако Java API фреймворка MapReduce оказалось достаточно сложным для не программистов. Ответом на этот вызов стало появление третьего слоя – целой плеяды различных средств обработки данных для пользователей, не знакомых с языком Java. К таким инструментам относятся: Hive – для работы с данными, расположенными в первом слое при помощи SQL-подобного языка; Pig, позволяющий описывать более сложные процессы трансформации данных при помощи функционального языка PigLatin; Mahout, Cascading, Scalding и пр. Главной общей чертой всех инструментов был общий механизм работы с данными – все они позволяли эффективно пользоваться инструментом MapReduce.То есть все Hive-запросы, равно как и скрипты на языке Pig, перед своим выполнением компилировались в одну или несколько MapReduce-работ и осуществлялись в рамках единого менеджера ресурсов. Таким образом, эти инструменты наследовали не только все достоинства MR, но и его недостатки, из которых в первую очередь стоит отметить ориентированность на пакетный режим работы.
Переход к быстрым данным
 Со временем жесткая привязка к единому механизму обработки стала превращаться в серьезный недостаток платформы, так как повысилась потребность в новых режимах работы с данными вследствие нескольких обстоятельств. Во-первых, существенно выросли запросы бизнес-пользователей на интерактивную аналитику данных в Hadoop. Во-вторых, появилась необходимость в потоковой обработке данных, например, препроцессинг веб-логов перед помещением их в кластер. Ну и, конечно же, увеличение объемов обрабатываемой информации потребовало кардинального ускорения процессов пакетной обработки данных. Таким образом, в определенный момент был сформирован запрос на переход от просто больших данных к быстрым большим данным.
Со временем жесткая привязка к единому механизму обработки стала превращаться в серьезный недостаток платформы, так как повысилась потребность в новых режимах работы с данными вследствие нескольких обстоятельств. Во-первых, существенно выросли запросы бизнес-пользователей на интерактивную аналитику данных в Hadoop. Во-вторых, появилась необходимость в потоковой обработке данных, например, препроцессинг веб-логов перед помещением их в кластер. Ну и, конечно же, увеличение объемов обрабатываемой информации потребовало кардинального ускорения процессов пакетной обработки данных. Таким образом, в определенный момент был сформирован запрос на переход от просто больших данных к быстрым большим данным.
Для удовлетворения перечисленных требований стали появляться новые инструменты: Impala, Kafka, Spark, Storm и множество других. Каждый из них прекрасно решал свой круг задач, однако ввиду отсутствия единого менеджера ресурсов не было возможности создавать кластеры, предназначенные для различных рабочих нагрузок.
Решить проблему позволила концепция Hadoop 2.0. Основой нового подхода стало выделение дополнительного слоя управления ресурсами (рис. 2). Работа этого слоя заключается в построении очереди выполняемых в кластере задач, выделении ресурсов выполняемым задачам, мониторинге процесса и перераспределении ресурсов в случае ошибок при их выполнении. Новым менеджером ресурсов стал фреймворк Yet Another Resource Negotiator (YARN), удобное API которого позволило быстро адаптировать наиболее распространенные инструменты больших данных для работы в среде YARN. Со временем появились альтернативные менеджеры ресурсов, такие как Mesos, однако серьезного распространения они не получили и до сегодняшнего дня остаются скорее экзотикой.
Применение быстрых данных
Интеграция в одном Hadoop-кластере множества различных технологий привела к стремительному разрастанию экосистемы. И сейчас в палитре архитекторов Big Data-систем есть множество различных инструментов, позволяющих не просто работать с большими данными, но и делать это быстро. Рассмотрим некоторые наиболее типичные сценарии, при которых необходима быстрая обработка больших данных.
Потоковая обработка данных
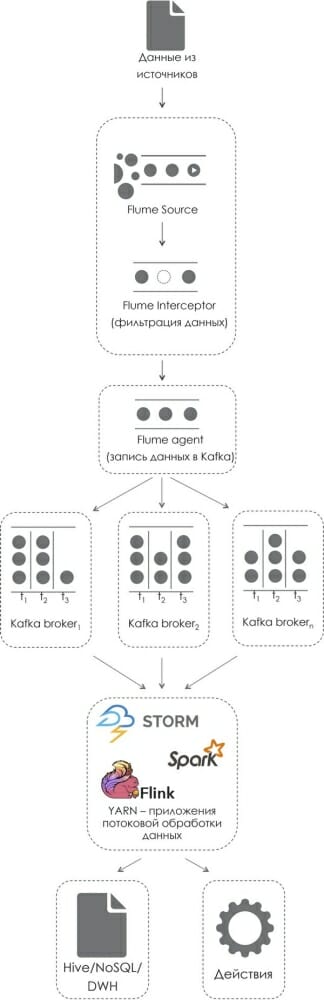
Необходимость обработки мощного потока данных существует в различных отраслях, это могут быть и системные журналы высоконагруженного веб-сервера, и данные с датчиков того или иного сложного промышленного оборудования, и набирающий популярность IoT (Интернет вещей), и многое другое. Общим для всех перечисленных примеров является набор этапов, которые проходят данные при обработке. На рис. 3 показана типичная архитектура подобного решения, основанная на платформе Hadoop. Данные проходят через ряд этапов, на каждом из которых работает специальная технология. Можно выделить три этапа: получение данных из источников, применение к ним какой-либо логики, сохранение результатов для дальнейшей аналитики. Рассмотрим технологии, задействованные в предлагаемой архитектуре.
Apache Flume – открытая технология потоковой передачи данных. Представляет собой децентрализованную систему передачи небольших пакетов информации, закодированной в виде так называемых Avro-сообщений. Архитектурно цепь передачи данных, построенная на основе фреймворка flume, выглядит как последовательность сервисов, называемых Flume Agent, между которыми передаются сообщения. Каждый Flume Agent состоит из цепочки различных элементов:
- Source – всегда первый элемент в цепочке. Обеспечивает чтение данных из источников и разбиение входящего потока данных на сообщения. Существует ряд стандартных реализаций источников: файлы, TCP-сокет, Twitter, syslog, Kafka. При этом обеспечивается возможность создания пользовательских реализаций источников;
- Chanel – канал, описывающий процесс передачи сообщений внутри агента. Существует ряд возможных вариантов: память, диск, РСУБД, Kafka и т. д. От выбранного канала зависят быстродействие и отказоустойчивость данного агента;
- Interceptor – опциональный элемент, предназначенный для модификации или фильтрации сообщений, проходящих через описываемый агент;
- Sink – элемент, описывающий то, куда передаются сообщения после обработки их в агенте. Существует множество стандартных Sink’ов: HDFS, Hive, Kafka, различные MQ.
Для обеспечения необходимого уровня быстродействия и отказоустойчивости возможны различные комбинации представленных агентов.
В рамках архитектуры всего решения Flume используется для получения данных из источников, при необходимости их фильтрации в interceptor’ах и помещения в систему гарантированной доставки сообщений Apache Kafka.
Apache Kafka – высокопроизводительный распределенный брокер сообщений. Разработан в компании LinkedIn. В отличие от других систем передачи сообщений легко масштабируется и может хранить сообщения какое-то время. Данные попадают в Kafka через объекты класса Producer, с помощью которых описываются различные поставщики информации. Внутри брокера сообщения делятся на темы, называемые топиками. Сообщения могут разделяться по ряду параметров для обеспечения оптимальной балансировки нагрузки. Одно сообщение может принадлежать одному или нескольким топикам. Работа системы строится в соответствии с двумя моделями:
- очередь – как только сообщение читается из топика одним потребителем, оно тут же удаляется из очереди;
- издатель-подписчик – сообщение сохраняется в очереди до тех пор, пока не будет обработано всеми потребителями.
По заявлениям компании LinkedIn, в их инфраструктуре через Apache Kafka проходит более миллиона сообщений в секунду.
В рамках архитектуры всего решения Apache Kafka предполагается использовать как буфер для входящих данных, работающий по принципу издатель – подписчик. В качестве издателя в нем будет выступать последний Flume-агент в цепочке чтения входящих данных. В качестве подписчиков могут использоваться различные недавно разработанные механизмы, предназначенные для быстрой обработки больших данных.
Механизмы быстрой обработки больших данных
Возросшие требования к скорости обработки больших данных обусловили появление ряда новых инструментов, способных заменить в качестве механизма исполнения классический MapReduce, ориентированный в основном на анализ данных гигантскими пакетами. Для потоковой обработки наиболее применимы Apache Spark и Apache Storm. Многообещающе выглядит и появившийся сравнительно недавно Apache Flink.
Самым распространенным на сегодня инструментом подобного рода является фреймворк Apache Spark. Благодаря вынесению работы с данными в память достигается высочайшая производительность. Задачи, написанные в рамках этого инструмента, могут выполняться под управлением менеджера ресурсов YARN. Благодаря API для языков Scala, Python и Java (с широким использованием Lambda-выражений Java 8) код приложений отличается компактностью и высокой читабельностью. Все перечисленные преимущества делают Apache Spark достойным преемником классического Hadoop MapReduce-алгоритма.
Существует несколько вариантов использования Apache Spark:
- пакетный режим – подобный классическому подходу MapReduce режим, в рамках которого большие порции данных обрабатываются по расписанию;
- потоковый режим (Spark—Streaming) – в этом режиме в памяти кластера постоянно находится Spark-задача, которая считывает данные из источника (источником могут выступать, например, TCP-сокет или Apache Kafka) и по мере считывания данных выполняет над ними операции в режиме, приближенном к реальному времени. Такой подход позволяет более равномерно во времени использовать вычислительные ресурсы кластера.
Apache Storm в отличие от Spark может работать только в режиме потоковой обработки. Для его работы выделяются на постоянной основе несколько YARN-контейнеров. Другим важным отличием Apache Storm от Spark является то, что он обрабатывает входящие сообщения не микробатчами, а потоком. Storm используется многими признанными мэтрами ИT-индустрии, такими как Twitter, Yahoo и Spotify.
Новый фреймворк Apache Flink является развитием идей, заложенных в Storm. Этот фреймворк не так давно вышел из Apache Incubator, однако один из ведущих разработчиков коммерческих Hadoop-дистрибутивов – компания MapR уже заявила о включении его в свой продукт.
В рамках описываемой архитектуры инструменты, подобные Spark, Storm и Flink, используются для очистки данных, применения к ним какой-либо логики (в том числе с включением алгоритмов машинного обучения), сохранения этих данных для использования в дальнейшей аналитике и, при необходимости, для инициации каких-либо действий.
В качестве слоя хранения в такой архитектуре могут использоваться HDFS (позволяющий работать с этими данными через SQL интерфейс Hive), нереляционные БД или корпоративные хранилища данных.
Несколько слов по поводу обеспечения отказоустойчивости систем потоковой обработки данных. Естественно, для таких систем обеспечение отказоустойчивости – задача несравненно более трудная, чем для систем, ориентированных на пакетную работу, в которых в случае отказа всегда можно перезапустить вычисления на тех же данных. Как же решается эта задача на каждом из этапов предложенной архитектуры?
Для начала рассмотрим базовые элементы программной инфраструктуры, на которой может быть построено подобное решение. Распределенная файловая система HDFS реплицирует данные между своими узлами, при этом данные сохраняют целостность в случае выхода из строя всех узлов уровня репликации, кроме одного. На случай выхода из строя мастер-узлов системы, где хранятся метаданные HDFS или Hive, а также работает центральная служба менеджера ресурсов, YARN предусмотрен механизм обеспечения высокой доступности, в рамках которого для критичных сервисов существуют дубликаты, автоматически занимающие место отказавших.
Проблема надежности в рамках Apache Flume решается через возможность параллельной работы на разных физических серверах нескольких агентов, обрабатывающих сообщения, которые приходят из системы-источника. Таким образом, с выходом из строя части серверов не происходит прерывания работы всей цепи передачи данных. При этом приходящие на агент сообщения записываются в очередь, чтобы при выходе из строя агента быть обработанными и переданными после его возвращения в работоспособное состояние.
Надежность в рамках Apache Kafka обеспечивается за счет репликации сообщений, проходящих через него по узлам кластера.
Различные фреймворки обработки данных, находящиеся в рамках рассматриваемой архитектуры за Apache Kafka, используют разнообразные механизмы поддержания работоспособности в случае выхода из строя оборудования, обеспечивая тем самым высокие показатели отказоустойчивости.
Приведем несколько примеров реализации подобной архитектуры.
Операторы услуг мобильной связи могут собирать поток данных о географическом положении своих пользователей, чтобы при попадании пользователя в какое-либо место (например, аэропорт) инициировать маркетинговые взаимодействия с этим пользователем (скажем, отправить СМС-сообщение «Не забыли ли вы подключить роуминг?»). Еще один пример применения такого стека технологий – различные системы сбора данных с датчиков, анализирующие в режиме реального времени параметры работы оборудования.
Сегодня на рынке существует несколько коммерческих решений, реализующих такую архитектуру. К примеру, в компании IBM существует продукт InfoSphere Streams. Для достижения наивысшей производительности разработчики IBM отказались от использования открытых Storm/Spark и написали собственный механизм потоковой обработки. Другой пример – компания Teradata, которая готовит к выходу продукт Teradata Listener, полностью построенный на открытых технологиях.
Следует отметить, что для потоковой обработки данных требуется более мощное аппаратное обеспечение с большим объемом памяти и более мощными процессорами, нежели для классических Hadoop-задач. Однако не предъявляется каких-то специфических требований к «железу», нет необходимости в SSD-дисках или связи узлов оптоволокном. Поэтому многие производители оборудования, выпускающие серверы, специально ориентированные на Hadoop, начали дифференцировать свои продуктовые линейки в соответствии с типом задач, которые предстоит решать их клиентам. Например, в последней версии платформы Teradata Hadoop Appliance существуют три версии серверов: Storage – ориентированные на использование в качестве экономически эффективного хранилища холодных данных, Balance – предназначенные для пакетных ETL-процессов и Performance – оснащенные большим количеством оперативной памяти и более быстрыми процессорами и дисками, благодаря чему они способны решать задачи по потоковой обработке данных и интерактивной аналитике.
Быстрая аналитика
Другой существенной претензией, которую традиционно предъявляли инструментам, основанным на MapReduce, является невозможность (или, мягко говоря, затрудненность) интерактивной аналитики данных. Для получения простых сведений о количестве уникальных пользователей крупного интернет-портала за месяц зачастую приходилось ждать несколько часов.
Первую попытку предоставить пользователям инструмент для быстрой аналитики данных в Hadoop-кластере предприняла компания Cloudera, включившая в свой дистрибутив CDH такой инструмент, как Impala, который работал по схеме, схожей с алгоритмом Massive Parallel Processing, принятом в мире корпоративных хранилищ данных. Однако до тех пор, пока не появился менеджер ресурсов YARN, совмещение в одном кластере Impala и каких-либо инструментов, использующих MapReduce, зачастую приводило к неработоспособности всего кластера.
С разработкой YARN появилась возможность использовать различные инструменты для работы с данными в Hadoop. Уже сегодня они предоставляют возможность аналитикам данных получать ответы на свои запросы за приемлемое время.
Один из старейших элементов Hadoop-экосистемы – фреймворк Hive – со временем «отвязался» от MapReduce как обязательного механизма исполнения запросов, и сегодня пользователи могут выбирать между различными механизмами – классический MapReduce, Tez или Spark. Два последних позволяют достичь значительного прироста в скорости работы.
Упоминавшийся Spark имеет собственную надстройку SparkSQL для работы с данными при помощи SQL-запросов. Cloudera Impala также может работать в YARN-контейнерах.
В компании Facebook был создан фреймворк Presto, который, подобно Impala, работает на основе собственного механизма, предоставляя интерфейс для быстрого выполнения аналитических запросов. Его отличительной чертой является возможность использовать в одном запросе данные из различных источников, не ограничиваясь данными, расположенными в Hadoop. К примеру, можно обращаться к данным в MySQL, Cassandra, Postgres в рамках одного запроса. Также существует программный интерфейс для реализации пользовательских коннекторов к различным источникам.
Важно отметить, что все перечисленные инструменты могут использовать одни и те же метаданные и имеют JDBC/ODBC-драйверы, что позволяет подключаться к ним при помощи сторонних инструментов, например, различных средств Business Intelligence.
Заключение
На сегодняшний день существует немало инструментов, позволяющих организовать по-настоящему быструю работу с большими данными, что дает пользователям возможность решать все более сложные проблемы. Однако нельзя не отметить и негативный тренд, связанный с тем, что растущее количество фреймворков, которые приходится использовать при выполнении задач, приводит к существенному усложнению архитектуры системы. В таких условиях использование готовых продуктов и услуг специализированных компаний по работе с большими данными становится широкой практикой.



