
руководитель отдела тестирования, «Инфосистемы Джет»


старший системный администратор, «Инфосистемы Джет»
Рано или поздно любые ИТ-системы заходят в тупик своего развития. И с этой ситуацией все чаще сталкиваются и крупные, и небольшие компании: несмотря на то что все они из разных сфер деятельности, проблемы у бизнеса схожие, а желание одно – правильно выстроить инфраструктуру ИТ-систем, а также процессы разработки и тестирования программного обеспечения.
До сих пор бизнесу казалось, что он может самостоятельно управлять процессами разработки и тестирования: только дайте людей! Однако наступает момент, когда поддерживать ту или иную систему становится совершенно невозможно – релизы слишком долгие, регрессионное тестирование распухло до нескольких месяцев, команды стали настолько большими, что становится невозможно ими управлять.
В этом материале мы расскажем о типовых проблемах развития ИТ-систем многих организаций, о причинах их возникновения и, самое главное, о способах их избежать.
Чаще всего когда компания приходит к нам на аудит, у нее уже случилось нечто неладное, что руководство компании больше не готово терпеть и принимать как данность: или айтишники выкатили релиз с ошибками на продуктив, потеряв миллионы за несколько минут, или не успели закончить разработку новой услуги в приложении, которую уже начали рекламировать по телевизору при очень дорогом предоплаченном эфирном времени, или расходы на ИТ стали превышать все разумные пределы и т. д.
Подробно разбирая подобные проблемы многих заказчиков, мы пришли к выводу, что три ключевые проблемы – долго, плохо, дорого – в разных компаниях возникают и решаются примерно одинаково. Причем, решая одну из них правильно, вы также закрываете и две другие проблемы.
Минимизация издержек
Бизнес всегда стремится решать ИТ-задачи оперативно и с минимальными издержками, не погружаясь в технические детали проекта. Нередко это ведет к упразднению «ненужных» и «дорогих» работ по автоматизации. Однако процессы решают все, и очень важно внедрять корректные алгоритмы взаимодействия ИТ-инфраструктуры и разработки с нуля – именно такой подход способен приносить бонусы еще много релизов подряд.
Все, кто хоть раз сталкивался с оценкой и защитой проекта, наверняка помнят, как однажды не удалось отстоять автоматизацию того или иного процесса. Она дает мгновенную экономию на отрезке нескольких лет – ровно до тех пор, пока вместо пары разработчиков у вас не будет сидеть целая команда, а регрессионное тестирование не начнет занимать два месяца. Именно тогда ИТ-система превращается в неуправляемого монстра. В этот момент вы быстро придумываете костыли для срочных доработок, которые вопреки всему проживут в системе до самого вывода ее из эксплуатации – так показывает практика. Зоопарк оборудования увеличивается, и уже непонятно, на каком «железе» живут тестовые, а на каком продуктивные системы; количество кода растет, и для поддержки изменений нужно все больше времени и людей; штат увеличивается, и управлять командой становится все сложнее.
Обычно бизнес привыкает к кривым процессам и, хоть и продолжает давить на ИТ по срокам, не видит выхода из этого замкнутого круга. Часто компании даже и не замечают проблем: они всегда были, и все с этим как-то жили. Поэтому развивать внутреннюю экспертизу либо приглашать консультантов, которые помогут увидеть проблемные места и зоны развития, – вот два пути, которые могут помочь выйти из этого замкнутого круга.
А правило тем временем звучит легко и отнюдь не революционно: все, что может быть автоматизировано, должно быть автоматизировано и настроено на регулярный запуск. Это позволяет сократить время и не раздувать штат сотрудников, поддерживающих рутину. Помимо этого сокращается влияние человеческого фактора: скрипт выполняет одно и то же действие из раза в раз, не устает, у него не замыливается глаз, он не допускает ошибок, работает по выходным и по ночам и даже не просит оплаты сверхурочных. Те компании, которые успешно внедрили у себя частные облака и конвейеры CI/CD (Continuous Integration & Continuous Delivery), не знают подобных проблем.
Автоматизация сборок
Процесс автоматизации сборок – это далеко не новая тенденция в управлении ИТ-системами. Первые описания процесса появились более 25 лет назад, и с тех пор он постоянно совершенствуется. На сегодняшний день концепция трансформировалась в полноценные конвейеры CI/CD, где обычный коммит в систему управления версиями запускает целую цепочку событий: сборку приложений, запуск различных видов тестирования, открытие и закрытие задач в трекерах, подготовку эксплуатационных инструкций и многое другое. Правильная архитектура таких процессов требует существенных затрат и компетенций, поэтому сегодня появился целый штат новых специалистов. Конечно, DevOps уже у всех на слуху, но хотелось бы глубже рассмотреть текущие и будущие перспективы этого направления.
Если раньше инициатива по автоматизации исходила преимущественно от самой команды разработки или эксплуатации, то сегодня бизнес-менеджмент, осознав все преимущества процесса автоматизации, все чаще привлекает DevOps-специалистов в погоне за уменьшением скорости выпуска своих цифровых продуктов. Глобально это приводит к росту двух рынков – как самих специалистов, так и специализированного ПО для управления автоматизированными конвейерами.
Исторически сильный Jenkins с открытым исходным кодом постепенно вытесняется проприетарными JetBrains, Teamcity и Atlassian Bamboo. У наших заказчиков сейчас популярны решения для статического анализа кода и тестирования уязвимостей, такие как SonarQube и Fortify. В области использования контейнеров популярен docker, а вот с применением оркестраторов интереснее: популярность Kubernetes растет, но крупные технологические компании предпочитают OpenShift с поддержкой от вендора.
Зачастую принятие решения использовать тот или иной продукт для CI/CD исходит из долгосрочной архитектурной модели и поставленных целей, но в любом случае результатом внедрения современных практик будет увеличение скорости выхода продукта на рынок, улучшение качества кода и уменьшение эксплуатационных расходов, хотя последнее неочевидно и требует отдельной проработки.
А что же в будущем? Один из главных трендов – это плавный переход к концепции Everything-as-Code («все как код»), т. е. применение наработанного опыта в области автоматизации сборок не только к инфраструктуре, но и различным бизнес-процессам. Сейчас еще сложно представить внутренний документооборот через коммиты в Git, но такая практика реализуется и все больше и больше рутинных процессов плавно переходит на рельсы автоматизации.
Автоматизация развертывания тестовых сред
Теперь обратим внимание на «железо», на котором будет происходить магия автоматических сборки и тестирования.
Чаще всего среда тестирования – это больше, чем просто виртуальный сервер. Она может включать, например:
- несколько виртуальных машин с серверами приложений, менеджерами очередей, балансировщиками нагрузки, веб-серверами и т. д.;
- процесс развертывания прикладного ПО;
- тестовый набор данных – обезличенный, ограниченный по глубине хранимой информации, иначе тестовые отчеты будут выполняться слишком долго;
- ресурсы системы хранения данных;
- сеть.
Чтобы настроить все это, используют оркестратор – ПО, которое может в определенной последовательности сконфигурировать все объекты ИТ-инфраструктуры.
Все наиболее развитые оркестраторы – BMC TrueSight Orchestration, MicroFocus Operations Orchestration, VMware vRealize Orchestrator и другие – имеют богатый перечень оборудования и ПО, которым они умеют управлять. Но начинают их внедрение обычно с решения, лежащего на поверхности: «давайте автоматизируем создание виртуальных машин и дадим возможность разработчику заказать себе виртуалку из портала самообслуживания». Это и будет частное облако.
Создание такой универсальной услуги по развертыванию виртуальной машины с удобной настройкой – непростая задача. Только представьте, сколько параметров необходимо учесть: число процессоров, объем памяти, количество виртуальных дисков, хранилищ и сетевых интерфейсов, возможность изменять все эти настройки в течение жизненного цикла сервера.
Но если оценить весь процесс создания среды тестирования или разработки, то окажется, что создание виртуальных машин – лишь небольшая часть затрачиваемых усилий и времени. По нашему опыту, непосредственно работы по настройке оборудования занимают не более 15% времени при создании тестовой среды. Бóльшая часть времени уходит на проведение миграции данных, развертывание ПО и интеграцию со смежными системами. Поэтому мы считаем, что при построении частных облаков стоит включать в каталог услуги по созданию сред бизнес-приложений, которые позволят проводить сквозное тестирование бизнес-процессов, а не только функциональные тесты отдельной системы. Преимущества такого подхода в эффективности использования тестовых сред, стабильности результатов тестирования (все среды абсолютно одинаковые) и гибкости использования.
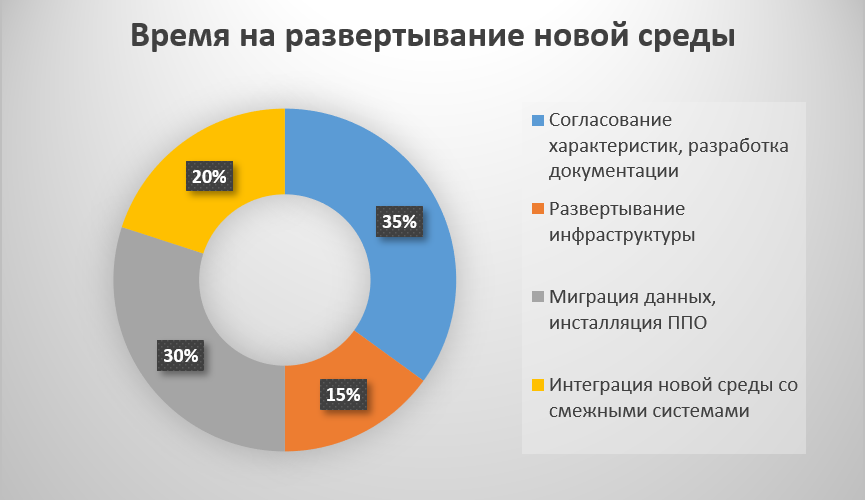
Источник: журнал JetInfo, №7-8 (291)/2018
Как могла бы выглядеть такая комплексная услуга по созданию среды? Предположим, полноценная среда интеграционного тестирования для приложения «X» состоит из СУБД, нескольких серверов приложений, распределенного брокера сообщений, нескольких веб-серверов и виртуального балансировщика, а также смежных систем. Полностью разворачивать всю эту конструкцию может быть слишком долго, особенно если СУБД содержит большой объем тестовых данных. Правильно будет разделить соответствующую услугу по созданию среды на две.
- развертывание постоянной части – СУБД, брокера, балансировщика и смежных систем (назовем это полигоном);
- развертывание серверов приложений и веб-серверов (назовем это средой).
Тогда полигон может разворачиваться один раз на длительное время, а среды, напротив, могут создаваться часто, причем в автоматическом режиме посредством вызова API системы автоматизации. Это позволило бы, например, тестировщикам добавить к сценариям автотестов создание и ликвидацию тестовых сред.
При этом жизненные циклы создания полигона и тестовой среды должны быть связаны, так как эксплуатация одного без другого теряет смысл. К сожалению, на момент написания статьи бóльшая часть средств автоматизации не позволяет это делать «из коробки» и требует определенной, пусть и не очень сложной доработки.
Перейдем к техническим средствам. Главный инструмент процесса автоматизации многими элементами инфрастурктуры – оркестратор. Его основная характеристика – гибкое управление как можно большим числом таких элементов, как серверы, виртуальные машины, системы хранения, сеть, терминальные сервисы, службы каталогов и пр.
Существуют как решения от известных производителей (BMC, Microfocus, IBM, Microsoft, VMware), так и open source продукты от Red Hat, Cloudify и др. По нашему опыту, при выборе нужно ответить на следующие вопросы о возможностях решения.
- Есть ли необходимые модули или компоненты по автоматизации нужного оборудования и ПО?
- Соответствует ли оно требованиям ИБ (например, безопасное хранение паролей управляемых систем)?
- Каковы средства управления жизненным циклом создаваемых сред и возможности по настройке ролевой модели?
- Возможна ли необходимая настройка графического интерфейса портала и средств отчетности?
- Есть ли возможность интеграции с публичными облаками?
О последнем пункте стоит поговорить отдельно. С одной стороны, большинство компаний сегодня с опаской смотрят на публичные облака. Сможет ли провайдер облака обеспечить необходимую доступность? Что делать, если что-то сломается? Как обезопасить данные? Все эти вопросы действительно важны, и маловероятно, что прямо завтра бизнес-критичные системы будут массово переноситься в облака. Но критичность сред разработки и тестирования ниже, а частота изменений в них выше. Это ли не идеальный кандидат на миграцию? Таким образом, возможность управлять ресурсами публичного и частного облаков из одного средства автоматизации станет критичной в самом ближайшем будущем, а это уже гибридное облако.
Вычислительные ресурсы внешнего облачного провайдера представляются в оркестраторе как среда виртуализации, аналогичная по возможностям локальным виртуальным инфраструктурам. Интеграция с ними не сложнее, чем настройка управления локальной фермой. Более сложной является задача обеспечить прозрачную миграцию приложений из частного облака в публичное и обратно. Например, если требуется временно расширить имеющиеся вычислительные ресурсы за счет внешних. Здесь многое будет зависеть как от архитектуры приложений, так и от инфраструктуры. Используется ли микросервисная архитектура или речь идет о монолитном приложении? Насколько интенсивен обмен данными между различными модулями приложения? Что за данные обрабатываются и каковы требования по их защите? Как обеспечить сетевую связность между облаками? Что стоит подчеркнуть, так это то, что автоматизация и оркестрация ИТ-инфраструктуры в гибридных средах – одна из четырех основных технологических тенденций этого года и последующих лет[1].
К выбору средства автоматизации нужно привлекать не только ИТ-специалистов, но и разработчиков, поскольку в их руках имеются инструменты CI/CD: например Jenkins или Gitlab, которые могут быть использованы как средства автоматизации. В частности, с помощью плагинов Jenkins может управлять созданием виртуальных машин. Если же средств автоматизации, имеющихся в инструментах CI/CD, окажется недостаточно, то рассмотрите возможность интеграции выбранного оркестратора с ними по REST (Representational State Transfer) API, так как следующим шагом после автоматизации развертывания среды будет ее включение в конвейер разработки и тестирования.

