В этом обзоре мы предлагаем посмотреть на то, что сегодня происходит в секторе дата-центров, какие определяющие векторы развития намечаются. Нашей целью является попытка понять, какие пути совершенствования ЦОД, какие модели архитектуры дата-центров ведут к устойчивому развитию в будущее, чтобы иметь возможность вовремя встроиться в набирающий обороты тренд и не остаться на обочине ИТ-прогресса.
Смена модели: от программно-центричной к дата-центричной
Структура дата-центра представляет собой довольно сложную конструкцию, в которой можно выделить различные составляющие – в зависимости от того, какую именно цель преследует проводимый анализ. Для нас наибольший интерес представляет динамика процесса, поэтому мы абстрагируемся от технологических особенностей и сосредоточим внимание на следующих ключевых блоках ЦОД: приложение, данные, инфраструктура.
Давайте вернемся в недалекое прошлое – середину 2000-х годов – и посмотрим, как тогда выглядело взаимодействие этих трех элементов. В типовой ситуации мы имели некую базу данных, на которую накладывалось работающее с ней приложение, – при такой структуре именно приложение определяло, как мы получали доступ к этим данным и что мы с ними могли делать. А уже под приложение, как правило, строилась выделенная классическая трехуровневая инфраструктура: Storage + сеть SAN + сервер, на котором, собственно, и работали различные части приложения. При такой схеме ЦОД обновление инфраструктуры проводилось вместе с обновлением приложения, поскольку они были намертво привязаны друг к другу.
Мы не претендуем здесь на хирургическую точность, но приблизительно в первой половине 2010-х гг. появилась технология виртуализации, которая предоставила цодостроителям уникальный шанс – вытащить инфраструктуру за пределы приложения. Благодаря этому появилась возможность размещать в ЦОД на единой инфраструктуре несколько приложений, при этом традиционная тесная связка «данные + приложение» сохранялась: данные все еще оставались внутри приложения, так что каждое приложение работало со своими данными.
Это был очень важный шаг вперед, который позволил развязать два ключевых цикла – цикл обновления приложений и цикл обновления инфраструктуры дата-центра. В прежней модели при устаревании инфраструктуры – физическом или моральном – приходилось осуществлять очень непростой, долгий, сложный, болезненный и, кстати, весьма дорогой процесс миграции приложения на новую инфраструктуру. Зачастую при такой миграции терялись данные, страдали пользователи, система долгое время оставалась недоступной, а компании теряли свои деньги.
Но как только стало возможным отвязать инфраструктуру дата-центра от приложения, появилась возможность обновлять отдельные элементы в инфраструктуре, не затрагивая работу самих приложений, жизненный цикл которых теперь мог быть как короче, так и длиннее жизненного цикла инфраструктуры ЦОД. Что касается последнего, то он, как правило, обновляется раз в два-три года, если у компании есть на это деньги.
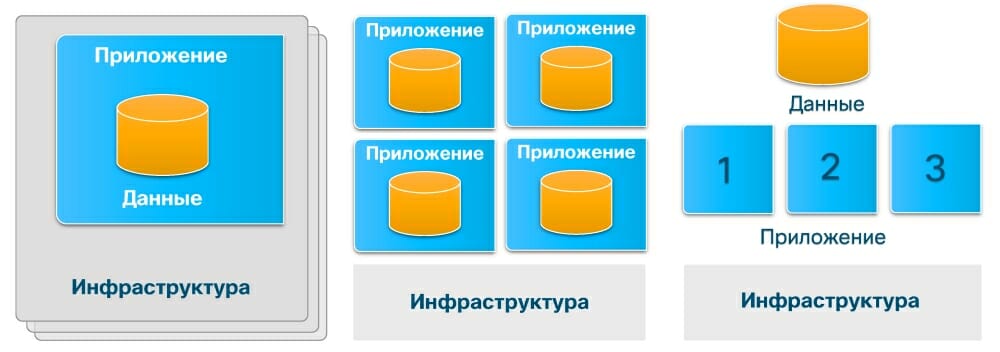
Если мы обратимся к тому, что сегодня происходит с моделью типичной инфраструктуры дата-центра, то увидим, что продолжается тенденция на постепенное расхождение трех основных элементов. Конечно, пока мы стоим в самом начале этого пути, но уже сейчас понятно: данные начинают отделяться от приложений, стремятся выходить из-под их непосредственного контроля.
Что это дает? Опять же изменение циклов обновления: за один жизненный цикл данных с ними успевают поработать несколько поколений приложений, которые, в свою очередь, получают автономность от цикла обновлений инфраструктуры. Кстати, эта тенденция находит свое отражение и в технологии контейнеризации: по умолчанию все данные, которые находятся в Docker-контейнере, исчезают вместе с ним. Если вы не предпримете специальных усилий по подключению Docker-контейнера к какой-то внешней базе, чтобы там остались результаты его работы, данные будут потеряны – здесь действует принцип «отработал – ушел».
В связи с этим интересно также отметить, что приблизительно в середине 2010-х годов в компании Cisco увлеклись технологией Intercloud: суть в возможности переносить из облака в облако (между разными гипервизорами) приложение вместе с данными. Однако через три-четыре года стало понятно, что заказчики не испытывают потребности перетаскивать приложения весте с данными – обычно они преследуют другую цель: поднять в облаке новое приложение (в облаке это проще, чем пытаться обновить старое), а уже к нему подтащить те данные, с которыми работало старое.
Итак, мы получаем новую модель инфраструктуры ЦОД, в которой все три ключевых элемента – приложение, данные, инфраструктура дата-центра – получили независимость, автономность друг от друга. И если вернуться к жизненному циклу обновления, то мы увидим, что самым продолжительным циклом обладают данные, на втором месте обычно оказываются приложения, а вот инфраструктура имеет самый короткий жизненный цикл – каждые два-три года нужно обновлять серверную начинку.
Справедливости ради отметим, что существует и противоположный подход – Agile, при котором максимально коротким жизненным циклом обладают приложения. Но вне зависимости от того, какой из трех элементов живет дольше, автономность помогает решать проблему их независимого обновления.
Автоматизация управления
Когда мы планируем внедрение какого-либо приложения, то составляем список требований, которые оно предъявляет к железу дата-центра: программное обеспечение делает запросы на процессорные мощности, память, дисковое пространство и т. п. Мы суммируем все эти требования и получаем необходимый для нормальной работы приложения пул ресурсов. В идеальном варианте нам хочется, чтобы этот пул ресурсов дата-центра был максимально гибким, позволяющим нам «нарéзать его на квадратики» и раздать приложениям.
Далее, с точки зрения сетевых требований из имеющегося пула ресурсов будут выходить какие-то виртуальные и физические интерфейсы. В идеальном случае хочется иметь между этими интерфейсами любые связи, скажем: такое-то приложение работает с этим, другое с тем, а вот здесь должна стоять стена, чтобы наши приложения напрямую не общались между собой. Проще говоря, ЦОД в идеальном мире выглядит так, что если внутри него что-то ломается, то инфраструктура сама решает эту проблему: например, сгорел коммутатор, но дата-центр продолжает работать.
Почему такая идеальная схема ЦОД сегодня не действует? Потому что настраивают конфигурацию ИТ-инфраструктуры люди. Традиционный способ настройки выглядит следующим образом: у нас есть много компонентов и каждый имеет свой интерфейс, так что администратор выполняет для каждого определенную последовательность действий. Чтобы настроить сервер, надо выполнить: операцию 1, операцию 2… операцию 22 – ура! сервер настроен. Затем мы должны повторить это для оставшихся 10, 50… 100 серверов инфраструктуры ЦОД.
При этом в реальном мире связка этих параметров, определяющая логику взаимодействия компонентов, зачастую происходит в голове у тех людей, которые производят настройку. Например, у администратора есть 5 конфигурационных файлов, и он пытается в своей голове решить, как пакеты попадают из одного сегмента сети в другой. В такой модели ручной настройки любой запрос на изменения в инфраструктуре вызывает новую цепочку событий, которую сложно продумать в голове. Администратор, конечно, старается учесть все моменты, но, как правило, что-то упускает из виду, поэтому, когда некая новая схема налажена, что-то может отвалиться в другом месте. Понятно, что при такой ручной настройке неочевидна связь элементов между собой, конфигурации разных сервисов хранятся вперемежку и т. д.
В идеальном ИТ-мире человек не должен этим заниматься, поэтому Cisco и предложила осуществлять управление инфраструктурой через профили. Каждая функция сервера и каждая функция приложения на уровне сети описывается конфигурационной единицей, которая и называется профилем (для серверов это сервисные профили, для сети – профили приложения). Профиль содержит все настройки для конкретного сервиса.
Положим, у нас есть профиль веб-сервера: у него должны быть определенные настройки, сервер должен с определенного места подтянуть свою операционную систему, он должен иметь какое-то количество интерфейсов (LAN, SAN) и все они должны быть вставлены в какие-то части сети. Все это хозяйство описывается в единой конфигурационной единице, которая загружается на централизованный контроллер. Затем этот контроллер идет в ИТ-инфраструктуру и прописывает там все настройки для веб-сервера, причем делает это во всех тех цепочках и местах, которые необходимы, чтобы он исправно работал.
Такая же идея и с сетью ЦОД: вы описываете свои приложения на уровне, скажем, «кружочков и стрелочек». Затем загружаете все это в контроллер, а он прописывает это в наборе коммутаторов, которые составляют сеть и работают как некое единое целое.
Ключевая идея здесь состоит в том, чтобы вывести конфигурацию инфраструктуры с низового уровня проставления пунктов в конфигурационных файлах на верхний уровень понимания, что это железо делает, – всю рутинную работу берет на себя контроллер. Компиляция набора профилей в итоговую конфигурацию выполняется автоматически.
Что это дает? Во-первых, автоматизацию рутинных операций. Во-вторых, уменьшение точек управления. Когда вы настраиваете обычную ИТ-инфраструктуру, необходимо сконфигурировать множество компонентов: серверы, коммутаторы, LAN, SAN и пр. В случае управления с помощью профилей все настраивается одной единицей, и если что-то ломается в инфраструктуре, то нет необходимости забираться в пять или пятьдесят разных мест.
В-третьих, такая схема работы обеспечивает преемственность конфигураций при смене поколений оборудования – фактически, мы освобождаем администратора от этой задачи: один и тот же сервисный профиль одинаково будет работать на серверах Cisco разных поколений (5 поколений серверов Cisco UCS; 4 поколения Fabric Interconnect; 3 поколения коммутаторов Nexus 9k). Если вы один раз настроили какой-то профиль и эта настройка всех устраивает, то при смене оборудования не придется заново перепрописывать все эти настройки – достаточно будет перенести профиль с одного сервера на другой.
Это же касается и решения Cisco ACI, предназначенного для автоматизации ИТ-задач и ускоренного развертывания приложений. Если вы один раз написали профиль какого-то приложения в сети, то затем его можно переносить между поколениями оборудования и не нужно будет настраивать вручную новые коммутаторы.
Далее, поскольку все конфигурации хранятся внутри контроллера, то по API их можно вытащить в виде XML-файлов. По сути дела, ваша сеть или вычислительная платформа становится самодокументирующейся. Затем уже с этой полученной информацией можно делать различные вещи, например: для ACI есть модуль, который в Java-скрипте может в браузере нарисовать всю схему (те самые «кружочки и стрелочки»), которая является не абстрактной моделью, а текущей конфигурацией сети со всеми параметрами. Кроме того, по API можно интегрироваться и с внешними инструментами автоматизации ЦОД – например, с UCS Director (программный продукт, который автоматизирует управление разнородной ИТ-инфраструктурой центра обработки данных).
Примерно такие же возможности Cisco стремится сейчас осуществить и для миграции приложений между облаками – это делает инструмент Cisco CloudCenter Suite (ранее известен как CliQr). Вы можете описать настройки приложения, а дальше CloudCenter, интегрированный с 15 публичными облаками и с семью вариантами организации частного облака, позволяет перемещать указанное приложение между облаками.
Точно так же как сервисный профиль в серверах абстрагирует конфигурацию сервера от конкретного железа, CloudCenter Suite абстрагирует конфигурацию приложения от той конкретной облачной платформы, в которой оно работает. В результате вам не нужно думать над тем, как создать сетевой сегмент в Amazon или в Azure, – система CloudCenter Suite делает это за вас.
Отметим и еще один важный момент: сегодня все активнее развиваются инструменты для аналитики в дата-центре. Например, такой инструмент, как Cisco Workload Optimization Manager (CWOM), смотрит на платформу виртуализации, собирает статистику и выдает рекомендации по ее оптимизации. Еще один полезный инструмент – Tetration Analytics – собирает информацию о сетевых пакетах, строит карты взаимодействия и позволяет оптимизировать трафик сети. С его помощью вы можете увидеть все сетевые потоки в ЦОД от порта одного приложения до порта другого.
Такая автоматизация ИТ-инфраструктуры позволяет снизить ТСО (Total Cost of Owneship) стоимости владения в среднем на 46% на горизонте трех лет (данные приводятся по отчету IDC за 2016 г.).
ЦОД через призму хранимых и обрабатываемых данных
Мы часто пишем о дата-центрах, технологиях, связанных с хранением данных и очень много внимания уделяем технической стороне вопроса: рассказываем о серверах, кабелях, маршрутизаторах, системах охлаждения и т. д. и т. п. Все это, безусловно, важные вещи, но не будем забывать о том, что они лишь средство, а целью являются данные. Данные – вот то единственное и неповторимое содержание дата-центра, которое заботит заказчика в первую, вторую и третью очередь.
Если мы попытаемся рассмотреть работу типового дата-центра с точки зрения того, какие же именно данные там обрабатываются, то увидим приблизительно следующую картину. Около 40% ЦОД (здесь и далее мы ссылаемся на данные, предоставленные Дмитрием Хороших, ведущим менеджером Cisco по развитию бизнеса в области ЦОД), как правило, приходится на диски виртуальных машин. Еще примерно 30% приходится на различные файловые хранилища – раньше все эти данные обычно лежали на распределенной инфраструктуре Windows-серверов, но после появления на рынке сравнительно недорогих мощных дисковых массивов у заказчиков появилась возможность держать на них так называемую файловую помойку. Далее, около 20% объемов ресурсов хранения ЦОД приходится, как правило, на резервное копирование: обычные бэкапы, более современные снапшоты и т. д. Возможно, следующая фраза покажется провокационной, но только 10% ресурсов хранения дата-центра сегодня приходится на те данные, ради работы с которыми лет 15 назад и покупался дисковый массив, – это тяжелые СУБД типа Oracle или SQL.
Для всех этих компонентов у компании Cisco имеются готовые решения, находящиеся в прайс-листе. Итак, для работы виртуальных машин существует стандартное, хорошо отработанное решение – универсальная гиперконвергентная платформа виртуализации Cisco HyperFlex, которая обладает простым управлением на основе политик и множеством вариантов расширения.
Для файловых хранилищ Cisco предлагает воспользоваться решениями своих партнеров – Scality и Cohesity (это файловые хранилища, которые строятся на базе обычных рековых серверов). Для резервного копирования Cisco может предложить решения от компаний Commvault и Veeam (готовые типовые валидированные дизайны). Эти инструменты обеспечивают гранулярное восстановление в нужном заказчику формате, возможность класть копии на ленту или в облако, репликацию VM на другую инфраструктуру, другую площадку или в облако и т. д.
Наконец, для оставшегося сегмента тяжелых баз данных Cisco предлагает порядка десятка партнерских решений от признанных производителей дисковых массивов: NetApp, EMC, IBM, Hitachi, Cloudera, OpenStack, Pure Storage и др.
Пока мы говорили лишь о традиционных типах данных. Однако сегодня, когда речь заходит о новых проектах, связанных, например, с Интернетом вещей, искусственным интеллектом и пр., появляются новые типы данных, о которых лет десять тому назад особо еще и не задумывались. Речь идет о больших данных и объектном хранении со своими способами организации и доступа (большие объемы неструктурированной информации). Так вот, и для этих новых типов данных у компании Cisco также имеются готовые, отработанные решения на Hadoop.
А теперь коротко остановимся на каждом типовом предложении. Cisco HyperFlex – идея этого решения достаточно простая: берем серверы, набиваем их дисками, с помощью ПО HX Data Platform делаем распределенное хранилище, с которым работают виртуальные машины. Какие преимущества дает такая платформа по сравнению с традиционными решениями? Во-первых, уменьшение номенклатуры вендоров и запчастей, которые физически участвуют в этом проекте (Storage, SAN, сервер, виртуализация, сеть). Во-вторых, HyperFlex – это полноценное, законченное решение (включая сетевую фабрику) для виртуализации, целиком построенное на решениях Cisco, и находится под единым зонтиком технической поддержки компании.
Для хранения вторичных данных (файловые архивы, разработка и тестирование, аналитические отчеты и т. п.) наиболее подходящим решением является Cohesity, работающее на серверах Cisco. Решение Cohesity обеспечивает заказчику практически безграничное масштабирование файлового хранилища и различные протоколы доступа (через API, блочные).
Для резервного копирования предлагается валидированный дизайн от Commvault и Veeam. Берется 4-юнитовый сервер Cisco S3260 с большим количеством дисков, который используется для хранения резервных копий – в качестве ПО здесь используется Veeam Availability Suite. Veeam получает доступ к снапшотам HyperFlex, что позволяет быстрее осуществлять резервное копирование и сокращать окно бэкапа.
Для тяжелых СУБД имеются типовые решения с партнерами Cisco: NetApp, EMC, IBM, Hitachi, Pure Storage и несколько решений типа OpenSource (OpenStack). На всех этих решениях красуется лейбл CVD (Cisco Validated Design) – это типовые валидированные дизайны: они означают, что заказчику не нужно каждый раз придумывать заново, как стандартный сервер подключить к стандартному хранилищу (сколько портов и как их соединять, как настраивать зонинг, мультипассинг). В типовом дизайне все уже описано – даны ответы на все вопросы. Более того, для таких типовых дизайнов можно разработать типовые способы по установке различных приложений. Большинство дизайнов имеют описания механизмов обеспечения отказоустойчивости.
Что же касается решений для больших данных, то у Cisco имеется инфраструктура – готовые типовые кластеры под Hadoop. Причем сейчас доступны все три основных дистрибутива – Hortonworks, MapR и Cloudera.
Наконец, для объектного хранения существуют решения от Scality и Cohesity, которые отличаются разным размером масштабирования кластеров. Такое объектное хранилище может содержать в себе все что угодно: данные любого размера, неструктурированные данные. Когда нужно добавить в хранилище место, вы просто ставите сервер с дисками и ПО, а система уже самостоятельно перераспределяет все данные.
В связи с этим можно отметить интересный тренд: хранить в объектном хранилище резервные копии – такой подход позволяет значительно повысить отказоустойчивость.
И над всей этой инфраструктурой располагается Cisco ACI – универсальная сеть для ядра центра обработки данных. Преемственность конфигураций, сеть как единый объект настройки – все это реализовано в ACI (Application Centric Infrastructure). Начиная с 4-й версии ПО, появилась возможность заводить в ACI облачные инфраструктуры – это означает, что современный дата-центр может, по сути дела, распространиться куда угодно – на удаленные площадки и в даже облака.
Итоги
Ключевым вектором развития современных ИТ (и не только в сфере дата-центров!) является очевидный приоритет данных. Кстати, об этом говорят не только специалисты компании Cisco. Так, на конференции NetApp Directions в 2018 г. Татьяна Бочарникова, глава представительства NetApp в России и странах СНГ, указала на то, что ключевым трендом современного этапа развития ИТ является приоритет данных, которые, с одной стороны, являются драйвером цифровой трансформации, а с другой – становятся все более очевидным и весомым активом любого бизнеса.
Из этого тренда логичным образом следуют и многие другие тенденции, часть из которых мы отметили в настоящем материале. В новой модели инфраструктуры ЦОД три ключевых элемента – приложение, данные, инфраструктура дата-центра – получают независимость, автономность друг от друга. При этом разъединение элементов парадоксальным образом приводит к их более тесному взаимодействию, поскольку дата-центр получает гибкость, которой он не обладал при классической структуре. Автономные элементы становится легче обновлять, изменять их роль и функциональные возможности и т. д.
На новый уровень выходит и автоматизация: человек все дальше уходит от рутинных операций и все больше внимания начинает уделять содержательной стороне процесса. Администратор не занят погружением в бесчисленные порты и протоколы благодаря появлению новых инструментов управления, он видит процесс работы ЦОД с позиции, назовем это так, «владельца и распорядителя данных».
В заключение отметим и еще один интересный и внутренне противоречивый процесс – взаимодействие крупных вендоров. С одной стороны, мы видим процесс поглощения «мелких» и средних компаний гигантами индустрии, которые сегодня хотят иметь свои решения во всех областях ИТ, а не только в своей приоритетной зоне. С другой стороны, мы можем наблюдать за тем, как крупные компании легко идут на контакт со своими конкурентами, чтобы иметь возможность предложить заказчикам наиболее популярные в отрасли решения, потому появляются совместные проекты Cisco, NetApp, IBM и других лидеров ИТ-отрасли.



